1月21日,寒武纪思元290智能芯片及加速卡、玄思1000智能加速器量产落地后首次正式亮相。思元290智能芯片是寒武纪的首颗训练芯片,采用台积电7nm先进制程工艺,集成460亿个晶体管,支持MLUv02扩展架构,全面支持AI训练、推理或混合型人工智能计算加速任务。

寒武纪首颗训练芯片思元290
寒武纪MLU290-M5智能加速卡搭载思元290智能芯片,采用开放加速模块OAM设计,具备64个MLU Core,1.23TB/s内存带宽以及全新MLU-Link™多芯互联技术,在350W的最大散热功耗下提供AI算力高达1024 TOPS(INT4)。
寒武纪玄思1000智能加速器整机,在2U机箱内集成4颗思元290智能芯片,高速本地闪存、Mellanox InfiniBand网络,对外提供高速MLU-Link™接口,实现系统级AI算力扩展,是AI算力的高集成度平台。
寒武纪训练产品线采用自适应精度训练方案,面向互联网、金融、交通、能源、电力和制造等领域的复杂AI应用场景提供充裕算力,推动人工智能赋能产业升级。
思元290采用MLUv02扩展架构
MLUv02架构为寒武纪MLU200全产品线共享,满足云、边、端三个场景的算力需求。云端训练对AI算力的要求更为苛刻,因此寒武纪对思元290的MLUv02架构进行了多项扩展,包括MLU-Link™多芯互联技术、高带宽HBM2内存、高速片上总线NOC以及新一代PCIe 4.0接口。相比寒武纪思元270芯片,思元290芯片实现峰值算力提升4倍、内存带宽提高12倍。新架构结合7nm制程,思元290可提供更优性能功耗比,以及多MLU芯片的扩展能力。
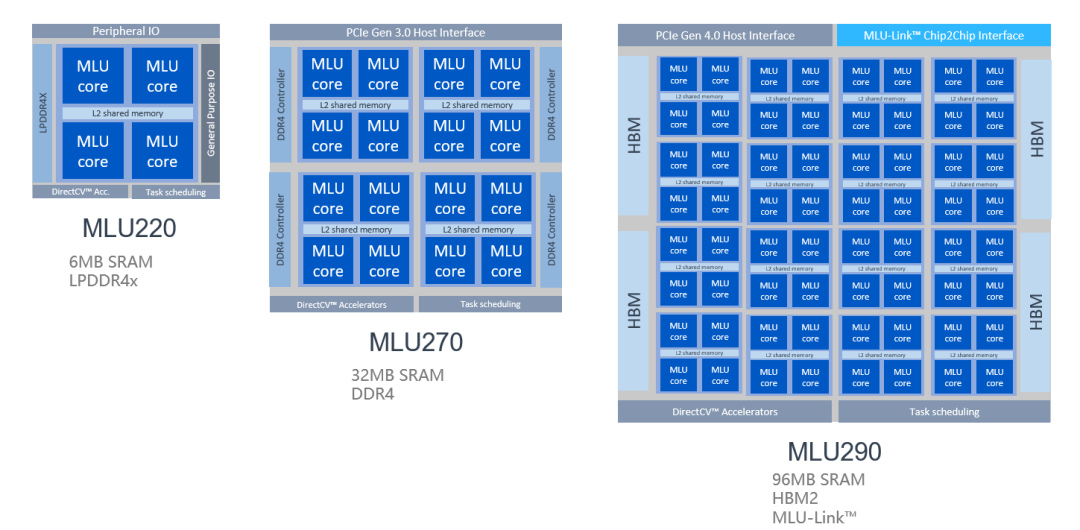
MLU290的MLUv02架构进行了多项扩展。
寒武纪MLU-Link™ 多芯互联技术
近年来,AI算法模型的复杂程度高速增长,对算力和训练速度提出了更高的要求。为了构建更强大的计算平台,多芯片间的互联技术已成为市场刚需。
寒武纪推出MLU-Link™多芯互联技术,并首次搭载于寒武纪思元290芯片,每颗思元290的多芯互联总带宽高达600GB/s。MLU-Link™具备丰富的互联特性,突破PCIe带宽和互联的瓶颈,相比思元270芯片通过PCIe并行的通讯方式,带宽大幅提升。MLU-Link™多芯互联技术支持多颗思元芯片无缝互联,可以端到端加速大型AI模型训练。
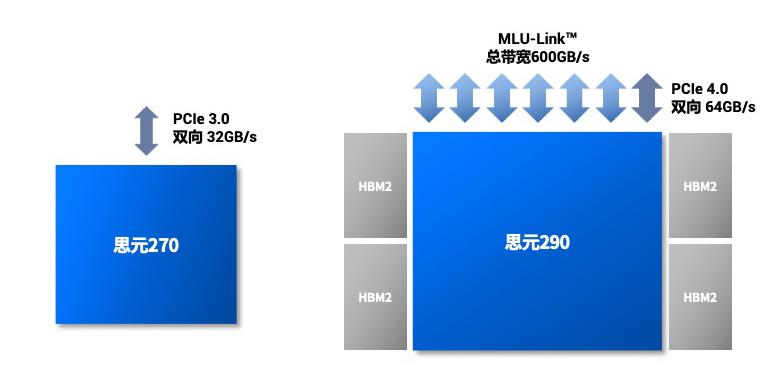
思元290采用MLU-Link™多芯互联技术进行互联,带宽、灵活性全面优于PCIe 3.0。
寒武纪首款AI训练智能加速卡MLU290-M5
寒武纪MLU290-M5智能加速卡搭载了思元290智能芯片,采用开放加速模块OAM设计,具备64个MLU Core,1.23TB/s内存带宽以及全新MLU-Link™多芯互联技术,在350W的最大散热功耗下提供AI算力高达1024 TOPS (INT4)。

寒武纪智能加速卡MLU290-M5

寒武纪智能加速卡MLU290-M5产品规格
寒武纪首款智能加速器玄思1000
寒武纪玄思1000智能加速器整机在2U机箱内集成了4颗思元290智能芯片,可实现AI算力多向扩展,满足性能、扩展性、灵活性、鲁棒性的要求。

玄思1000是AI算力的高集成度平台,支持计算、存储和网络同步扩展。
重塑AI算力架构
算力、算法、数据是人工智能发展的三大要素,随着这几年AI的逐步发展,算力的核心地位更为突出。人工智能技术落地于实际应用中需要芯片和硬件层面强大的算力支撑。算力已成为驱动AI产业化和产业AI化发展的关键要素。
下一代AI算力架构要求多智能芯片无缝协同、并行运行的同时,还能保持高计算效率,从而满足AI应用对算力的要求。寒武纪玄思1000智能加速器重新思考了未来AI算力架构的定义,为玄思1000提供MLU-Link™和InfiniBand网卡的混合多芯互联技术进行通讯,使得思元290智能芯片的计算力可进一步扩展。

玄思1000支持8个400G MLU-Link™和2个200G网络接口。
玄思1000配置8个对外互联的MLU-Link™接口,支持跨系统互联构建MLU POD。标准配置支持MLU POD 16、24、32。在POD内部,所有290芯片均可通过MLU-Link™多芯互联技术进行通讯,在带宽和延时方面实现了突破;POD外部通过玄思1000内置的网卡与其他系统进行通讯,实现了AI训练集群性能、扩展性和鲁棒性的协同提升。
寒武纪训练软件栈
寒武纪软件栈为思元290芯片提供完善的软件及应用生态,支持业界主流的TensorFlow和PyTorch等人工智能框架,用户不需要改变使用习惯,即可在思元290芯片上实现图形图像、语音、NLP、搜索推荐等多种应用的训练和推理。其中,基于Horovod分布式训练框架与MLU-Link™多芯互联技术相互配合,让思元290在单机多卡、多机多卡的场景下达到业界领先的训练加速比。寒武纪基础软件平台提供完善的开发工具包和社区支持,帮助用户在思元290芯片进行方便、灵活的定制开发及部署工作。配合强大的BANG智能编程语言及配套调试工具,用户可以为自定义的算法提供最佳性能调优。
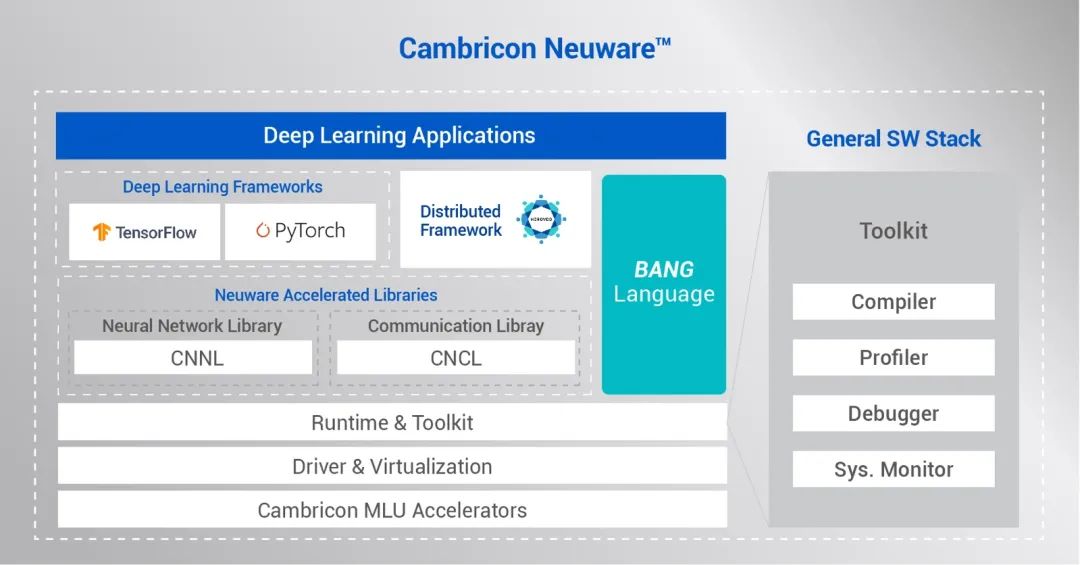
寒武纪软件栈为思元290芯片提供完善的软件及应用生态。
寒武纪思元290芯片及加速卡已与部分硬件合作伙伴完成适配,并已实现规模化出货。寒武纪首颗训练芯片思元290智能芯片及加速卡、玄思1000智能加速器训练产品线的集中亮相,标志着寒武纪已建立“云边端一体、软硬件协同、训练推理融合”的新生态。寒武纪将面向多样化的人工智能应用场景与需求,持续开展智能芯片及其基础系统软件的研发和产品化,为人工智能技术在各行业的广泛应用提供底层算力支撑。