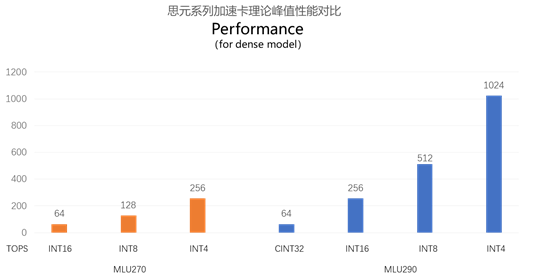
寒武纪思元290芯片,采用创新性的MLUv02扩展架构,使用台积电7nm先进制程工艺制造,在一颗芯片上集成了高达460亿的晶体管。芯片具备多项关键性技术创新, MLU-Link™多芯互联技术,提供高带宽多链接的互连解决方案;HBM2内存提供AI训练中所需的高内存带宽;vMLU帮助客户实现云端虚拟化及容器级的资源隔离。多种全新技术帮助AI计算应对性能、效率、扩展性、可靠性等多样化的挑战。

思元290基于MLUv02架构进行了多项扩展,实现峰值算力提升4倍、缓存带宽提高12倍、芯片间通讯带宽提高19倍。新架构采用7nm制程,可提供更高性能功耗比,以及多MLU系统的扩展能力。

MLU-Link™多芯互联技术,首发于寒武纪思元290芯片,总带宽高达600GB/s,支持思元芯片间互联和跨系统互联,可实现纵向扩展,满足AI模型训练的需要。

寒武纪虚拟化技术vMLU,支持在思元290上实现4个相互隔离的AI计算实例,每个实例独占计算、内存和编解码资源,在虚拟化环境下仍可保持不低于90%的极高效率,帮助客户充分利用硬件资源。

寒武纪基础软件平台采用端云一体架构,支持寒武纪全系列产品共享同样的软件接口和完备生态,可方便地进行AI应用的开发,迁移和调优,轻松实现云端开发训练模型,终端部署应用。

思元290采用寒武纪自适应精度训练方法。自适应精度训练可自适应调整人工智能模型不同层、不同数据类型的量化参数,同时量化参数调整周期也是自适应的,可在保证精度要求的基础上提高能效比。

思元290承载了32G高带宽内存(HBM2),单芯片内存带宽高达1.23TB/秒,是思元270芯片的 12倍,有效解决传统加速器芯片内存带宽瓶颈问题,为用户提供更高的模型训练速度。